Đề thi ngày 1: PDF.
Các bạn có thể xem video lời giải của VNOI ở đây.
Nguồn đề mình lấy của bạn Trí Phan ở trong Discord của VNOI.
Bài 1: NOEL
- Tag: DP LIS
Tóm tắt
Cho một hoán vị \(a\) gồm \(n\) phần tử. Cần chọn ra \(b\) là dãy con của \(a\) gồm \(2 \times m\) số sao cho \(\lvert b[i] - b[i + m] \rvert \le D, \forall 1 \le i \le m\) và \(m\) lớn nhất.
Lưu ý: \(1 \le D \le 5\)
Lời giải
Subtask 1: \(n = 10\)
Do \(n\) nhỏ nên ta có thể sinh nhị phân ra toàn bộ dãy con của \(a\), sau đó kiểm tra điều kiện đề bài. Độ phức tạp là \(O(2^n * n)\).
Subtask 2: \(n \le 100\)
Việc chọn ra dãy \(b\) độ dài \(2 \times m\) cũng giống như là việc chọn ra 2 dãy con \(c\), \(d\) với độ dài \(m\) và thoả điều kiện phần tử cuối cùng của \(c\) đứng trước phần tử đầu tiên của \(d\) trong hoán vị \(a\). Ví dụ \(b\) là: \([4, 5, 1, 3]\) thì \(c\) là \([4, 5]\) và \(d\) là \([1, 3]\), giống như việc bạn chia dãy \(b\) ra làm 2 nửa trái phải ấy.
Khi tới đây, nhiều bạn nghĩ tới bài này là 1 bài quy hoạch động cơ bản giống như bài tìm dãy con chung dài nhất (khi \(D = 0\) thì đúng là nhìn giống thật), và ra một công thức quy hoạch động kiểu: \(F[i][j]\) là “dãy con chung” dài nhất khi xét tới vị trí \(i, j\) của mảng \(a\), cách làm như sau:
\[F[i][j] = \begin{cases} max(F[i - 1][j], F[i][j - 1]), \text{if} \space \lvert a[i] - a[j] \rvert > D \\ F[i - 1][j - 1] + 1, \text{if} \space \lvert a[i] - a[j] \rvert \le D \end{cases}\]Độ phức tạp của thuật toán này là \(O(n^2)\).
Nhưng thuật toán trên không đúng, vì từ công thức trên, các bạn đã “vô tình” xem \(a\) là thành 2 mảng riêng, và không còn giữ điệu điều kiện giữa \(c\) và \(d\) mà mình đã nói ở trên.
Vậy tới đây ta phải làm sao? Đơn giản thôi, ta chia dãy \(a\) ra thành 2 dãy trái và phải, và quy hoạch động trên 2 dãy đó thay vì dãy \(a\) ban đầu. Việc chia dãy \(a\) ra thì có \(n\) cách chia (giống như đặt vách ngăn ở giữa mảng), với mỗi cách chia thì ta lại quy hoạch động mất \(O(n^2)\), do đó độ phức tạp là \(O(n^3)\), đủ tốt cho subtask này.
Subtask cuối: \(n \le 1000\)
Với subtask này, việc dùng thuật toán vừa trình bày ở trên sẽ không khả thi, thuật toán trên gồm 2 bước:
- Chia dãy \(a\) ra làm 2 dãy trái phải (có \(O(n)\) cách chia)
- Với mỗi cách chia, ta phải quy hoạch động trong \(O(n^2)\)
Ta có thể thấy thuật toán trên chưa tận dụng được điều kiện của đề bài: \(D\) nhỏ, do đó ta có thể nghĩ tới một hướng tối ưu mà có tận dụng tới điều kiện trên.
Xem lại 2 bước trên, bước 1 rất khó để tối ưu xuống, do đó ta nên tập trung vào bước 2 để giảm độ phức tạp thuật toán.
Nhìn kỹ lại công thức QHĐ:
\[F[i][j] = \begin{cases} max(F[i - 1][j], F[i][j - 1]), \text{if} \space \lvert a[i] - a[j] \rvert > D \\ F[i - 1][j - 1] + 1, \text{if} \space \lvert a[i] - a[j] \rvert \le D \end{cases}\]Ta có thể thấy với mỗi \(i\), chỉ có nhiều nhất \(2 * D\) chỉ số \(j\) thoả mãn \(\lvert a[i] - a[j] \rvert \le D\) (vì \(a\) là hoán vị). Ta sẽ tận dụng điều này để tối ưu thuật toán.
Ta nhìn vào test này, với \(D=1\)
Dãy \(a\): \([1, 5, 3, 7, 2, 8, 6, 4]\). Giả sử ta phân dãy \(a\) ra thành: \([1, 5, 3, 7 \mid 2, 8, 6, 4]\) thì:
- Số 1 có thể ghép được với số 2 (ở vị trí 5)
- Số 5 có thể ghép được với số 6, 4 (ở vị trí 7, 8)
- Số 3 có thể ghép được với số 2, 4 (ở vị trí 5, 8)
- Số 7 có thể ghép được với số 8, 6 (ở vị trí 6, 7)
Việc chọn ra dãy \(b\) chính là chọn từng số bên trái và ghép với số bên phải sao cho các vị trí được chọn ở bên phải tạo thành dãy con tăng. Ví dụ ta chọn các cặp số (1, 2) và (5, 4), thì ta có thể thấy vị trí của số 2 và 4 (là 5 và 8) tạo thành 1 dãy con tăng. Lại ví dụ ta chọn các cặp số (1, 2), (5, 6) và (3, 4), vị trí của các số 2, 6, 4 (là 5, 7, 8) tạo thành 1 dãy con tăng.
Ta có thể phát biểu bài toán theo cách này: ta có một mảng gồm nhiều đoạn, ở mỗi đoạn ta cần chọn ra nhiều nhất 1 số, sao cho các số được chọn ra phải là dãy con tăng.
Bài toán này thì liên quan gì tới bài toán cũ của chúng ta?
Với mỗi số bên trái, sẽ có một số vị trí bên phải (không quá \(2\times D\)) có thể ghép được với số đó, thì ta xem các vị trí này là thành một “đoạn”. Ví dụ vẫn với cách phân dãy \(a\) trên, thì mảng gồm các đoạn là:
\([5 \mid 7, 8 \mid 5, 8 \mid 6, 7]\) (| biểu thị cho phân tách đoạn, lưu ý mảng này lưu vị trí của số trong mảng \(a\) chứng không phải lưu giá trị).
Tới đây, việc chọn các cặp số (1, 2), (5, 6) và (3, 4) từ dãy \(a\) (ứng với vị trí 5, 7, 8 ở bên phải) cũng ứng với dãy con tăng ở mảng trên và thoả điều kiện mỗi đoạn chỉ được chọn nhiều nhất 1 số.
Vậy làm sao để giải quyết bài toán tìm dãy con tăng của mảng có nhiều đoạn, mà mỗi đoạn không được chọn nhiều số? Liệu với thuật toán tìm dãy con tăng mà ta thường dùng, có cách nào để đảm bảo việc mỗi đoạn chỉ chọn nhiều nhất 1 số hay không? Câu trả lời là có, và cách làm là: ở mỗi đoạn, ta sắp xếp các phần tử trong đoạn giảm dần, sau đó chỉ cần áp dụng thuật toán tìm dãy con tăng cơ bản là được.
Ví dụ: thay vì ta lưu mảng là \([5 \mid 7, 8 \mid 5, 8 \mid 6, 7]\) thì ta sắp xếp từng đoạn giảm dần: \([5 \mid 8, 7 \mid 8, 5 \mid 7, 6]\), ta có thể bỏ luôn dấu phân cách: \([5, 8, 7, 8, 5, 7, 6]\). Sau đó áp dụng thuật toán tìm dãy con tăng trên mảng mới này.
Tại sao cái này đúng? Bởi vì ta đang tìm dãy con tăng, khi mà mỗi đoạn ta sắp xếp giảm dần thì rõ ràng không thể chọn 2 phần tử của 1 đoạn được vì nó sẽ tạo thành dãy giảm.
Tóm lại, ta cần: tạo ra mảng các đoạn, sắp xếp giảm dần các đoạn, chạy thuật toán tìm dãy con tăng. Bước này tốn tất cả là \(O((n \times D \times log(n \times D)))\) độ phức tạp, do độ dài mảng các đoạn là \(O(n \times D)\), tìm dãy con tăng thì mất thêm log. Để cho đơn giản trong việc viết độ phức tạp, do \(D\) nhỏ nên mình loại bỏ \(D\) đi (cho tiện), ta có thể xem độ phức tạp là \(O(nlogn)\).
Vậy, ta đã cải tiến được bước quy hoạch động từ \(O(n^2)\) xuống \(O(nlogn)\), tới đây thì độ phức tạp toàn bài toán là \(O(n^2logn)\), đủ tốt để chạy subtask này.
Nhận xét
Bài này nhiều bạn dễ ngộ nhận về việc quy hoạch động tìm dãy con chung (như mình đã nói ở subtask 2), dễ dẫn tới sai nếu không test cẩn thận.
Về subtask full thì mình cảm thấy khá là khó nghĩ ra trong giờ thi nếu như các bạn chưa từng chuyển bài toán LCS thành LIS bao giờ. Còn với những bạn đã biết cách chuyển thì cũng cần có cái nhìn tinh tế, phải thật sự hiểu cách chuyển thì mới áp dụng sang bài này được.
Fact không fun: Lúc mình nghĩ ra thuật subtask 2, mình không nghĩ ra cách để optimize nó sang subtask 3, mặc dù mình cũng muốn chuyển LCS -> LIS, nhưng mà lúc đó lú nên không nghĩ tới :’(.
Bài 2: COMNET
- Tag: Knapsack on tree
Tóm tắt đề bài:
Có một cây gồm \(n\) đỉnh, cần đếm số cách chọn ra \(k\) đỉnh sao cho số cạnh ít nhất cần dùng để làm \(k\) đỉnh này liên thông nằm trong đoạn từ \(L\) tới \(R\).
Lưu ý: \(k\) nhỏ.
Lời giải:
Subtask 1: \(n \le 100, k = 2\).
Với \(k = 2\), ta cần chọn ra 2 đỉnh, số cạch để làm 2 đỉnh liên thông chính là khoảng cách giữa 2 đỉnh đó. Do đó, ta chỉ cần duyệt qua mọi cặp đỉnh và tính khoảng cách giữa chúng, độ phức tạp \(O(n^3)\)
Subtask 2: \(n \le 100, k = 3\).
Thay vì duyệt 2 đỉnh như subtask 1, ta có thể duyệt cả 3 đỉnh với độ phức tạp \(O(n^3)\), tính số cạnh cần dùng trong \(O(n)\) bằng DFS. Tổng độ phức tạp sẽ là \(O(n^4)\), sẽ khoảng 10^8 phép tính, vẫn đủ an toàn để chạy trong 1 giây.
Cách tính số cạnh cần dùng bằng DFS, ta tạm xem 3 đỉnh được chọn là \(a, b, c\):
- Xem gốc của cây là \(a\)
- Một đỉnh \(u\) được gọi là quan trọng nếu như trong cây con gốc \(u\) có chứa đỉnh \(b\) hoặc \(c\).
- Số cạnh cần dùng chính bằng số đỉnh quan trọng trừ đi 1.
Mã giả như sau:
bool DFS(u):
nếu u = b hoặc u = c thì u là đỉnh quan trọng;
duyệt v kề với đỉnh u:
Nếu DFS(v) đúng thì ta suy ra u là đỉnh quan trọng;
return u có là đỉnh quan trọng hay không;
...
gọi DFS(a);
Tuy vậy, vẫn có cách tính số đỉnh quan trọng trong \(O(1)\):
số đỉnh quan trọng \(= \frac{dist(a, b) + dist(b, c) + dist(a, c)}{2}\)
Subtask 3: \(n \le 100, k = 4\).
Subtask này thì nếu ta duyệt qua 4 đỉnh rồi lại kiểm tra trong \(O(n)\) thì độ phức tạp sẽ lên tới \(O(n^5)\), ta có thể áp dụng cách tính nhanh số đỉnh quan trọng trong \(O(1)\) tuy nhiên mình sẽ không đi theo hướng giải này.
Tạm thời ta xem lại 1 chút thuật toán ở subtask2, sau khi duyệt qua 3 đỉnh \(a, b, c\), ta có thể vẽ cây như sau:
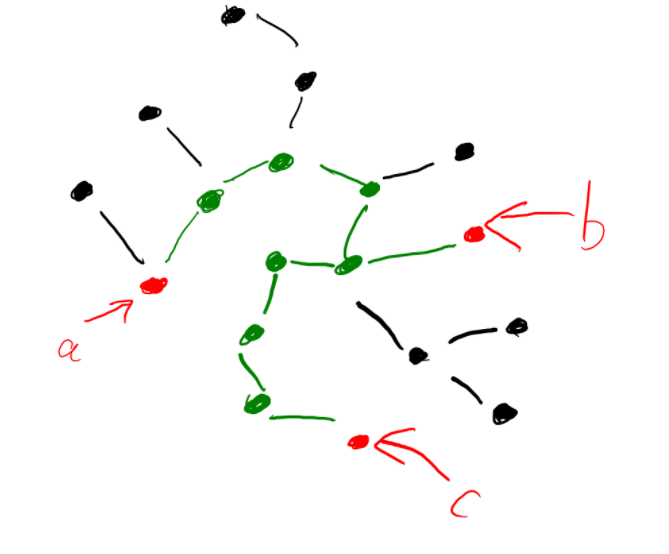
Chú thính:
- Xanh lá: đỉnh quan trọng
- Đỏ: đỉnh \(a, b, c\) (lưu ý \(a, b, c\) cũng là đỉnh quan trọng, mình chỉ tô khác cho dễ nhìn thôi)
- Đen: các đỉnh khác
Ta có thể thấy, việc chọn thêm 1 đỉnh thứ 4, sẽ làm tăng số cạnh lên đúng bằng số cạnh đen. Mà số cạnh đen lại chính là số cạnh trên đường đi ngắn nhất từ đỉnh đó tới các đỉnh xanh/đỏ. Điều này dẫn ta tới việc khi ta có 3 đỉnh \(a, b, c\) và ta muốn thêm đỉnh \(d\) vào, thì ta không cần DFS lại để tính trong \(O(n)\) mà có thể tính trong \(O(1)\)
Ta làm như sau:
- Duyệt qua 3 đỉnh \(a, b, c\) (\(O(n^3)\)), với mỗi cách duyệt:
- Tìm ra các đỉnh quan trọng như subtask 2 (\(O(n)\))
- Tình \(G(u)\) là khoảng cách ngắn nhất từ đỉnh \(u\) tới 1 đỉnh quan trọng bất kì. Ta có thể tính mảng \(G\) bằng kỹ thuật BFS nhiều nguồn (\(O(n)\))
- Duyệt qua đỉnh \(d\) để tính kết quả (\(O(n)\))
Độ phức tạp: \(O(n^4)\). Tuy nhiên, thật tình mà nói thì mình nghĩ subtask này người ra đề muốn chúng ta làm thuật quy hoạch động, thay vì thuật mình vừa trình bày.
Subtask 4: \(n \le 1000, k = 3\).
Với subtask này thì độ phức tạp \(O(n^4)\) hay cả \(O(n^3)\) đều không khả thi.
Nhận xét: với 3 đỉnh \(a, b, c\), sẽ có 1 và duy nhất 1 đỉnh thỏa mãn nếu cắt đỉnh đó đi khỏi cây thì \(a, b, c\) sẽ nằm ở 3 thành phần liên thông khác nhau. Ta tạm gọi đỉnh đó là đỉnh cắt. Và lưu ý rằng đỉnh cắt cũng có thể là 1 trong 3 đỉnh \(a, b, c\).
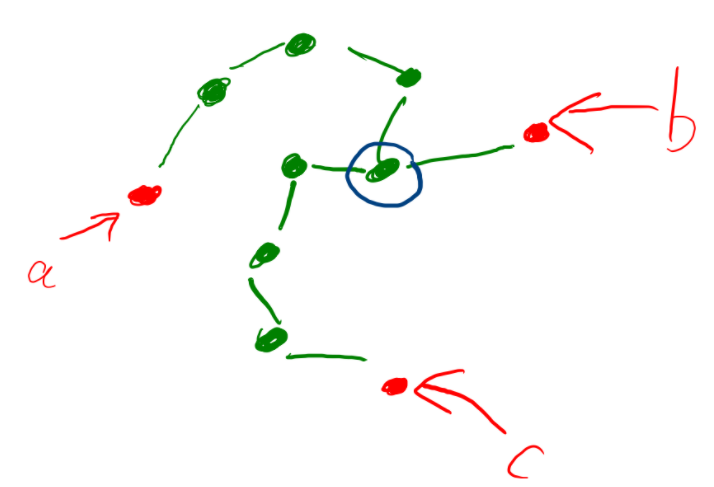
Trên hình, đỉnh cắt chính là đỉnh được được khoanh tròn.
Từ nhận xét trên ta có thể nghĩ tới việc duyệt qua đỉnh cắt, sau đó đếm số cách chọn 3 đỉnh \(a, b, c\) nằm ở 3 cây con khác nhau sao cho tổng khoảng cách tới đỉnh cắt nằm trong đoạn \(L, R\).
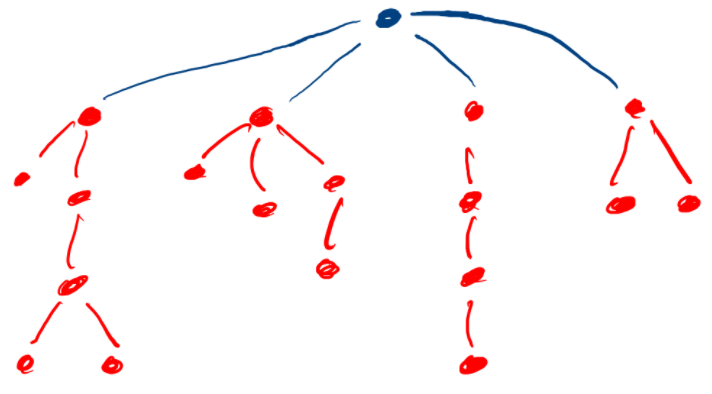
Như trên hình, đỉnh cắt là đỉnh xanh dương, đỉnh này phân ra 4 nhánh con, ta cần chọn ra 3 đỉnh, mỗi đỉnh nằm ở mỗi nhánh khác nhau.
Tới đây, bài toán quy về như sau:
- Ta có \(m\) vector \(V_1, V_2, V_3, \dots, V_m\) các số (với \(m\) chính là số con của đỉnh cắt). Vector \(V_i\) lưu các khoảng cách (số cạnh) từ các đỉnh trong cây con \(i\) đi tới đỉnh cắt.
- Ta cần chọn ra 3 số trong 3 vector \(V_a, V_b, V_c\) khác nhau sao cho tổng của 3 số này nằm trong đoạn \(L, R\).
Bài toán này ta có thể làm dễ dàng bằng QHĐ cái túi:
- Gọi \(F[i][sum][k]\) là số cách chọn ra \(k\) số từ các vector \(V_1, V_2, \dots, V_i\), với tổng các số đã chọn là \(sum\).
Cách tính \(F[i][sum][k]\):
- Ta duyệt qua từng số trong vector \(i\), tạm gọi số đó có giá trị là \(x\):
- Nếu ta chọn \(x\): \(F[i][sum][k] += F[i - 1][sum - x][k - 1]\);
- Nếu ta không chọn \(x\): \(F[i][sum][k] += F[i - 1][sum][k]\);
Khởi tạo \(F[0][0][0] = 1\) và \(F[0][0][1] = 1\) (Vì ta có thể chọn điểm cắt cũng là 1 số).
Kết quả chính là tổng của \(F[m][sum][3]\) với sum duyệt từ \(L\) tới \(R\).
Chung quy lại thuật toán của ta sẽ qua các bước như sau:
- Duyệt qua các đỉnh cắt
- Với mỗi đỉnh cắt thì tính lại hàm quy hoạch động \(F[i][sum][k]\).
Trên thực tế, khi cài đặt ta có thể chỉ dùng mảng 2 chiều khi QHĐ để tiết kiệm bộ nhớ cũng như thời gian.
Để đánh giá độ phức tạp của thuật toán này, nếu chỉ nhìn vào các vòng for mà đánh giá thì độ phức tạp của nó sẽ là \(O(n^3 * K)\) hoặc thậm chí là \(O(n^4 * K)\).
Tuy nhiên, nếu cài đặt tối ưu, duyệt các trạng thái quy hoạch động một cách hợp lý thì độ phức tạp của toàn bộ thuật toán này chỉ là \(O(n^2 \times K)\).
 (.O.)
(.O.)
Phần chứng minh độ phức tạp mình sẽ dẫn chứng ở subtask 5.
Subtask 5: \(n \le 1000, k = 4\)
Với 4 đỉnh thì ta không còn đỉnh cắt nữa, nhưng từ subtask 4 nó cho ta 1 hướng đi mới đó là dùng Quy hoạch động để đếm số cách chọn 3 đỉnh, tiếp tục theo hướng nghĩ này thì ta sẽ dùng thuật toán Quy hoạch động cái túi trên cây (Knapsack on tree) để làm. Kiến thức này đã được cho ra trong bài 6 năm ngoái.
Hàm QHĐ có thể làm như sau: \(F[u][sum][k]\) chính là số cách chọn \(k\) đỉnh trong cây con gốc \(u\), sao cho số lượng cạnh để \(k\) đỉnh đó liên thông với đỉnh \(u\) là \(sum\).
Để tính hàm \(F\) cho từng đỉnh \(u\) thì ta có thể làm giống như ở subtask 4, nhưng lưu ý rằng mỗi subtree bây giờ ta có thể chọn nhiều hơn 1 đỉnh:
- Gọi \(G[u][i][sum][k]\) là số cách chọn \(k\) đỉnh trong cây con gốc \(u\) khi xét các cây con \(V_1, \dots, V_i\), số lượng cạnh cần dùng là \(sum\).
- Với mỗi cây con \(v\) thứ \(i\) của \(u\):
- \[G[u][i][sum][k] += G[u][i - 1][sum - (cntEdge_v + 1)][k - k_v] * F[v][cntEdge_v][k_v]\]
- Với \(k_v\) là số đỉnh ta chọn từ cây con \(v\), và \(cntEdge_v\) chính là số cạnh để đối \(k_v\) đỉnh đó. Lưu ý tưởng hợp \(k_v = 0\)
Trong thực tế, ta không cài đặt hàm \(G\) mà ta sẽ tính trực tiếp trên mảng \(F\) để tiết kiệm thời gian và bộ nhớ.
Thuật toán trên có độ phức tạp O(N^2 * K^2), dù nghe rất vô lý. Các bạn có thể tham khảo phần chứng minh ở comment này: https://codeforces.com/blog/entry/52742?#comment-367974
Code tham khảo: COMNET.cpp
Nhận xét:
Bài này nhiều subtask nên cũng có nhiều kiểu chiến thuật làm bài cũng như là thuật toán khác nhau, mình nghĩ sẽ còn nhiều hướng giải khác cho các subtask nhỏ. Bài này nếu như chưa biết Knapsack on tree thì làm thuật chuẩn trong giờ rất khó, tuy nhiên 2 subtask đầu rất dễ và chiếm tới 50% số điểm nên các bạn duyệt trâu cũng đã có một lượng điểm kha khá.
Bài này mình thấy cài thuật AC còn dễ và ngắn hơn cài thuật trâu đối với các bạn đã biết Knapsack on tree, và kiến thức này cũng đã có trong đề thi năm trước (mặc dù nó là bài 6).
Bài 3: OR
- Tag: DP SOS, Bao hàm loại trừ, Tổ hợp
Tóm tắt đề bài:
Cho một dãy \(a\) gồm \(n\) phần tử. Đếm số cách chọn một dãy con \(b\) của \(a\) có \(K\) phần tử sao cho tổng or của dãy con đó chia hết cho 3, và nằm trong đoạn từ \(L\) tới \(R\). Nói cách khác:
- \[v = b[1] \mid b[2] \mid \dots \mid b[K]\]
- \[L \le v \le R\]
- \[v \pmod 3 = 0\]
Lời giải:
Nhận xét chung: điều kiện chia hết cho 3 chỉ để cho vui, nó không làm bài toán khó lên hay dễ đi, cho nên trong lời giải mình sẽ không bàn tới nó.
Trong lời giải mình có dùng 1 số thuật ngữ mà mình đặt ra để cho tiện nói, mình sẽ định nghĩa ở đây:
- Nói số \(a\) là tập con của số \(b\) nếu \(b \And a = a\) (phép and), hay nói cách khác là mọi bit của \(a\) đều xuất hiện trong \(b\). Ta ký hiệu luôn \(a \subset b\) nghĩa là \(a\) là tập con của \(b\).
- \(nBit\): số bit cần dùng để biểu diễn số \(a[i]\) (khoảng 20 đối với giới hạn bài toán \(a[i] = 10^6\))
Subtask 1: \(n \le 20\).
Subtask này \(n\) nhỏ nên ta chỉ cần sinh nhị phân dãy \(a\) và kiểm tra điều kiện or.
Sinh nhị phân là phần cơ bản trong đệ quy quay lui, mình thì thích cách viết đệ quy dưới đây:
void trau(int i, int len, int or_value) {
if (i > n) {
if (len == K && L <= or_value && or_value <= R && or_value % 3 == 0)
ans += 1;
return;
}
trau(i + 1, len, or_value); //không chọn phần tử i
trau(i + 1, len + 1, or_value | a[i]); //chọn phần tử i
}
Độ phức tạp \(O(2^n)\)
Subtask 2: \(n \le 200, a[i] \le 200\)
Với subtask này, nếu ta nhìn kỹ hơn vào các tham số của hàm trau ở subtask 1, ta có thể thấy các tham số đều đủ nhỏ để có thể lưu vào 1 mảng 3 chiều, do đó ta có thể dùng kỹ thuật đệ quy có nhớ (aka quy hoạch động) ở đây.
Có một việc đáng lưu ý ở đây là: do tham số or_value phụ thuộc vào \(a[i]\) nên nhiều bạn tạo mảng có dạng \(f[200][200][200]\) điều này là sai, bởi vì tuy \(a[i] \le 200\) nhưng giá trị or của chúng có thể lớn hơn 200, chính xác phải là \(255\) (lấy 128 or với 127 là có).
Độ phức tạp của thuật toán đệ quy có nhớ (aka quy hoạch động) này là: \(O(n^2 * 2^8)\)
Subtask 3: \(n \le 1\,000\,000\), \(a[i]\) có dạng luỹ thừa của 2, \(L = R\).
Do \(L=R\) nên ta chỉ cần or ra 1 giá trị duy nhất (là \(L\)). Do đó ta chỉ cần đảm bảo mọi bit 1 của \(L\) đều được xuất hiện trong các giá trị được chọn.
Tuy nhiên, đếm số cách chọn ra \(k\) số để or lại bằng \(L\) là không đơn giản. Ta chỉ có thể đếm được số cách chọn ra \(k\) số để or lại là tập con của \(L\). Chẳng hạn nếu ta có \(cnt[L]\) là số số \(a[i]\) là tập con của \(L\), thì số cách chọn ra \(k\) số để tổng or là tập con của \(L\) chính bằng \(C^k_{cnt[L]}\).
Từ đây ta có thể dùng bao hàm loại trừ để đếm được số tập con có tổng or chính bằng \(L\). Các bạn có thể đọc thêm về bao hàm loại trừ ở thư viện VNOI: Bao hàm loại trừ
Cách tính như sau: đặt \(f[i] = C^k_{cnt[i]}\) (với \(cnt[i]\) chính là số số trong mảng \(a\) là tập con của số \(i\)) .
Do \(a[i]\) đều có dạng luỹ thừa của 2 nên việc tính \(cnt[i]\) đơn giản, ta có thể duyệt qua bit của \(i\) và đếm số lượng phần tử của \(a\) có bit tương ứng, ta có thể tính toàn bộ mảng \(cnt\) trong \(O(n \times nBit)\).
Kết quả chính bằng: \(\sum_{i \subset L)} sign(mask) \times f[mask]\). Với \(sign(mask)\) là \(-1\) nếu mask khác tính chẵn lẻ về số bit so với \(v\), ngược lại \(sign = 1\).
Việc tính kết quả này chính bằng số tập con của \(L\), ta có thể xem nó là \(O(L)\).
Chung quy lại, thuật toán gồm 3 bước:
- Tính mảng \(cnt\) (\(O(n \times nBit)\))
- Tính mảng \(f\) (\(O(n)\))
- Tính kết quả bằng bao hàm loại trừ (\(O(L)\))
Độ phức tạp: \(O(n \times nBit)\)
Subtask 4: \(n \le 1\,000\,000\), \(L = R\).
Ở subtask này việc tính \(cnt[i]\) không còn đơn giản nữa bởi vì \(a[i]\) không còn có dạng luỹ thừa của 2. Do vậy, ta cần giải quyết việc đếm này.
Tới đây ta cần 1 kỹ thuật khác để tính mảng \(cnt\) chính là kỹ thuật DP SOS - Quy hoạch động Sum over subset. Việc tính mảng \(cnt\) chính là những gì DP SOS giải quyết. Cho nên ta chỉ cần áp dụng thẳng vào thì ta sẽ tính được mảng \(cnt\) trong độ phức tạp \(O(2^{nBit} * nBit)\).
Vậy ta chỉ cần thay bước 1 của thuật toán ở subtask 3 thành DP SOS là được.
Độ phức tạp: \(O(2^{nBit} * nBit)\)
Subtask 5: \(n \le 1\,000\,000\)
Tới đây, ta không chỉ tính 1 kết quả cho \(L\) nữa, mà ta cần tính kết quả cho mọi số trong đoạn \([L; R]\). Ta không thể cứ với mỗi số lại bao hàm loại trừ lại được, vì mỗi lần bao hàm loại trừ rất tốn thời gian.
Ở subtask 3, ta được làm quen với bao hàm loại trừ. Ở subtask 4, ta phải dùng DP SOS. Từ 3 và 4 suy ra, ta cần làm bao hàm loại trừ tối ưu bằng DP SOS ở sub 5 = ))).
Bước cải tiến này tập trung vào bước 3 của thuật toán, ta làm như sau: sau khi tính được mảng \(f\) ở bước 2, ta thân thêm hệ số 1/-1 vào \(f[i]\). Nếu \(i\) có lẻ bit thì ta nhân 1, nếu \(i\) có chẵn bit 1 thì ta nhân \(-1\).
Sau đó tính DP SOS của mảng \(f\), tạm gọi mảng được tính là \(g\). Lúc này, \(\lvert g[i] \rvert\) đúng bằng số lượng tập con có \(k\) phần tử có tổng or đúng bằng \(i\).
Tóm lại, ta có các bước sau:
- Tính mảng \(cnt\) bằng DP SOS (\(O(2^{nBit} \times nBit)\))
- Tính mảng \(f\) (\(O(n)\))
- Thêm hệ số vào mảng \(f\), tính DP SOS của mảng \(f\) (\(O(2^{nBit} \times nBit)\))
- Tính kết quả bằng mảng DP SOS vừa tính được ở bước 3 (\(O(n)\))
Nhận xét:
Đây là một bài khó, yêu cầu một kiến thức lạ đó là DP SOS, kiến thức này lần đầu được cho trong đề thi HSG. Theo mình thấy DP SOS là kiến thức cũng ít được nhắc tới khi ôn vòng 1, thường những bạn aim giải cao ở TST hay APIO mới cày. Mình thậm chí lúc chuẩn bị học vòng 2 mới được anh Mofk bảo là học DP SOS đi, lúc đó mới biết nó là gì :v.
Nhận xét ngày 1:
Mình thấy đề rất hay, để lấy 50% điểm của ngày 1 là không khó. Tuy nhiên, để AC bất kì bài nào trong đề đều yêu cầu một lượng kiến thức tốt cùng với thật sự hiểu những gì mình đã học, phải có tư duy mở rộng vấn đề. Ví dụ bài 1 thì có yêu cầu chuyển từ LCS -> LIS. Bài 2 là Knapsack on tree nhưng cũng không quá cơ bản. Bài 3 thì yêu cầu hiểu rõ DP SOS có thể làm được gì. Để AC được cả 3 bài thì đúng là yêu cầu một lượng kiến thức rất khủng. Đề cũng đánh vào tư duy nhiều hơn là code, mình thấy cả 3 bài nếu code thuật chuẩn thì tương đối là dễ code.
Mình rất thích đề này, nhưng khả năng cao là vào thi mình sẽ bị đề này đập tơi tả :’(.